Understanding and Applying Convolutional Neural Networks: Exploring Effective Uses of CNN
convolutional neural networks (CNN) have revolutionized the field of deep learning, particularly in the realm of image processing and computer vision. In this article, we delve into the intricacies of CNN, exploring their applications and effectiveness in various domains.
Introduction
Welcome to the introduction section where we will explore the basics of Convolutional neural networks (CNN) and their significance in the field of deep learning. CNNs have emerged as a powerful tool in image processing and computer vision, revolutionizing the way machines perceive and interpret visual data.
Introduction to CNN
Convolutional Neural Networks, commonly referred to as CNNs, are a class of deep neural networks that have shown remarkable performance in tasks such as image recognition, object detection, and medical imaging. The key idea behind CNNs is to mimic the visual cortex of the human brain, where neurons respond to overlapping regions in the visual field.
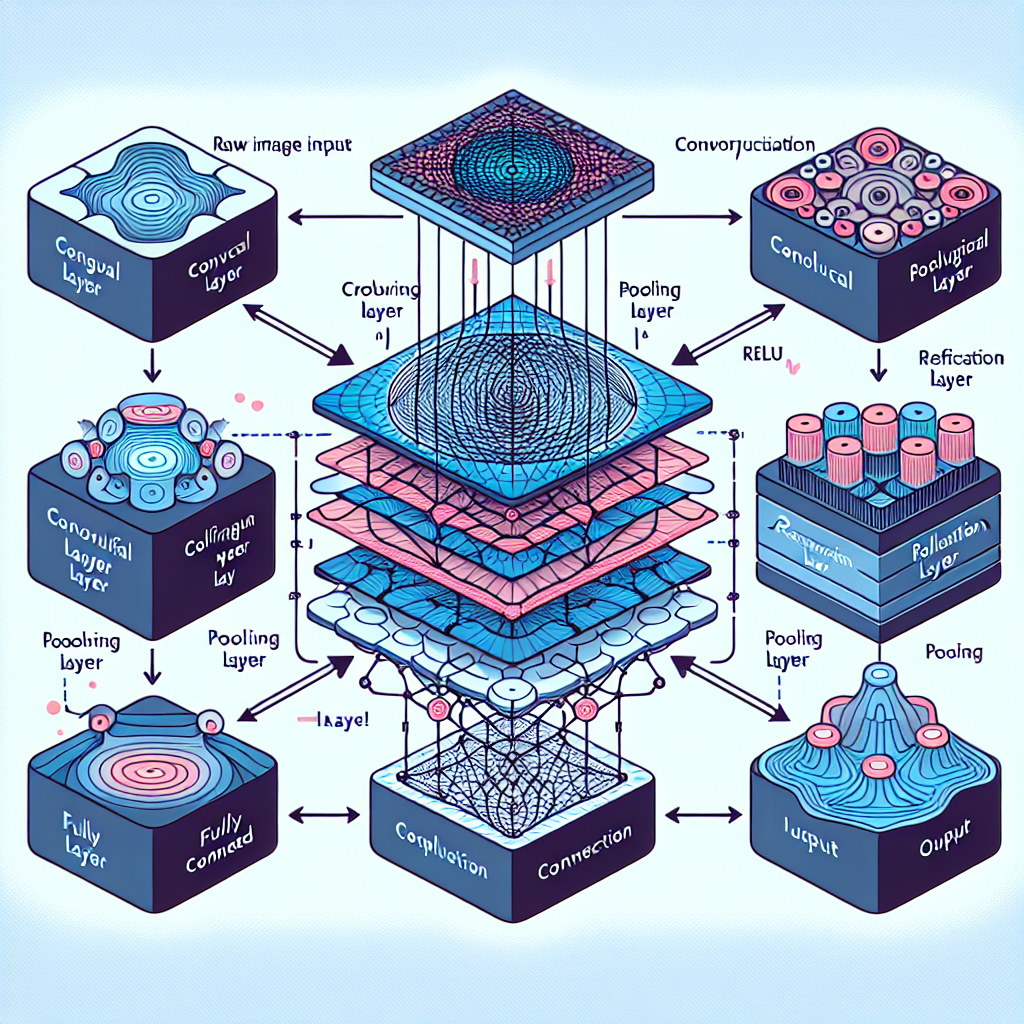
One of the fundamental components of CNNs is the convolutional layer, which applies filters to input data to extract features such as edges, textures, and patterns. These features are then passed through activation functions like ReLU to introduce non-linearity into the network.
Pooling layers are another essential part of CNNs, which downsample the feature maps obtained from convolutional layers to reduce computational complexity and prevent overfitting. Common pooling techniques include max pooling and average pooling, which help in retaining the most relevant information while discarding redundant details.
Architectural design plays a crucial role in the performance of CNNs, with models like LeNet-5, AlexNet, and VGGNet setting benchmarks in image classification tasks. These architectures vary in terms of the number of layers, filter sizes, and Connectivity patterns, showcasing the versatility of CNNs in handling diverse datasets.
The training process of CNNs involves backpropagation, where the network learns from errors and adjusts the weights of connections to minimize loss. optimization algorithms like Adam, SGD, and RMSprop are used to update the network parameters efficiently, leading to faster convergence and improved performance.
practical applications of CNNs span across various domains, including image recognition, object detection, and medical imaging. CNNs have been instrumental in achieving state-of-the-art results in tasks like facial recognition, autonomous driving, and disease diagnosis, showcasing their wide-ranging Impact.
performance evaluation of CNNs is done using metrics like accuracy and inference speed, which measure the model’s ability to classify images correctly and make predictions in real-time. Achieving high accuracy while maintaining fast inference speed is a key challenge in deploying CNNs in production environments.
challenges and limitations of CNNs include issues like overfitting, where the model performs well on training data but fails to generalize to unseen examples. Techniques like data augmentation, which involves generating new training samples from existing data, can help alleviate overfitting and improve the robustness of CNNs.
Looking ahead, future trends in CNN research are focused on exploring new architectures, optimization techniques, and applications in emerging fields like augmented reality, robotics, and natural language processing. The adoption of CNNs in industries like healthcare, finance, and entertainment is expected to grow, driving innovation and advancements in AI technology.
In conclusion, Convolutional Neural Networks have paved the way for significant advancements in deep learning and computer vision, offering a powerful framework for processing visual data and solving complex tasks. By understanding the principles and applications of CNNs, we can harness their potential to drive innovation and create intelligent systems that enhance our daily lives.
Basic Concepts
In this section, we will delve into the fundamental concepts of Convolutional Neural Networks (CNNs) that form the building blocks of their architecture. Understanding these basic concepts is crucial for grasping the inner workings of CNNs and their applications in various domains.
Convolutional Layers
Convolutional layers are the core components of CNNs that perform the operation of convolution on input data. This process involves applying filters to the input image to extract features such as edges, textures, and patterns. By convolving the input data with learnable filters, convolutional layers can capture hierarchical representations of visual information.
The output of a convolutional layer, known as a feature map, highlights the presence of specific features in the input data. These feature maps are generated by sliding the filters over the input image and computing the dot product at each position. Convolutional layers play a crucial role in feature extraction and are essential for the success of CNNs in tasks like image recognition and object detection.
Pooling Layers
Pooling layers are another key component of CNNs that help in reducing the spatial dimensions of the feature maps obtained from convolutional layers. Pooling operations like max pooling and average pooling downsample the feature maps by aggregating information from local regions. This downsampling process helps in reducing computational complexity and making the network more robust to variations in input data.
By discarding redundant information and retaining the most relevant features, pooling layers contribute to the efficiency and effectiveness of CNNs. Pooling also aids in creating translation-invariant representations, where the network can recognize patterns regardless of their exact position in the input data. Overall, pooling layers play a vital role in enhancing the performance of CNNs in tasks requiring spatial hierarchies.
Activation Functions
Activation functions are non-linear transformations applied to the output of a neuron in a neural network. In the context of CNNs, activation functions like Rectified Linear Unit (ReLU) introduce non-linearity into the network, enabling it to learn complex patterns and relationships in the data. ReLU is a popular activation function due to its simplicity and effectiveness in combating the vanishing gradient problem.
Other activation functions used in CNNs include Sigmoid and Hyperbolic Tangent (Tanh), which were commonly employed in earlier neural network architectures. Activation functions play a crucial role in enabling CNNs to model complex data distributions and make accurate predictions. By introducing non-linearities, activation functions allow CNNs to capture intricate patterns and nuances in the input data, leading to improved performance in various tasks.
Architectural Design
Architectural design is a critical aspect of Convolutional Neural Networks (CNNs) that significantly impacts their performance and efficiency in various tasks. Different CNN architectures have been developed over the years, each with its unique characteristics and capabilities.
LeNet-5
LeNet-5, developed by Yann LeCun in the 1990s, is one of the pioneering CNN architectures that laid the foundation for modern deep learning. This architecture consists of several convolutional and pooling layers, followed by fully connected layers, making it suitable for tasks like handwritten digit recognition.
The LeNet-5 architecture introduced concepts like convolutional layers and subsampling, demonstrating the effectiveness of hierarchical feature extraction in image recognition tasks. Despite its simplicity compared to more recent architectures, LeNet-5 remains a benchmark for early CNN designs.
AlexNet
AlexNet, introduced by Alex Krizhevsky, Ilya Sutskever, and Geoffrey Hinton in 2012, marked a significant breakthrough in deep learning by winning the ImageNet competition. This architecture consists of multiple convolutional and pooling layers, along with dropout regularization to prevent overfitting.
AlexNet’s success can be attributed to its deep architecture, efficient use of GPU acceleration, and the incorporation of ReLU activation functions. By demonstrating the power of deep CNNs in image classification tasks, AlexNet paved the way for the development of more complex architectures.
VGGNet
VGGNet, developed by the Visual Geometry Group at the University of Oxford, is known for its simplicity and uniform architecture. This network architecture consists of multiple convolutional layers with small 3×3 filters, followed by max pooling layers for spatial downsampling.
VGGNet’s straightforward design and focus on depth rather than width have made it a popular choice for various image recognition tasks. Despite its computational intensity due to the large number of parameters, VGGNet has demonstrated impressive performance on benchmark datasets.
Training Process
Training a Convolutional Neural Network (CNN) involves the iterative process of adjusting the network’s parameters to minimize the error between predicted and actual outputs. This section explores the key components of the training process, including backpropagation and optimization algorithms.
Backpropagation
Backpropagation is a fundamental algorithm in training neural networks, including CNNs. It involves propagating the error backward through the network to update the weights of the connections. By calculating the gradient of the loss function with respect to each parameter, backpropagation enables the network to learn from its mistakes and improve its performance over time.
The backpropagation process starts with the forward pass, where input data is fed through the network to generate predictions. These predictions are compared to the ground truth labels to compute the loss, which quantifies the difference between the predicted and actual outputs. The backward pass then calculates the gradients of the loss function with respect to each parameter using techniques like chain rule and gradient descent.
By adjusting the weights and biases of the network in the opposite direction of the gradient, backpropagation aims to minimize the loss and improve the model’s accuracy. This iterative process of forward and backward passes continues until the network converges to a set of optimal parameters that yield the best performance on the training data.
Optimization Algorithms
Optimization algorithms play a crucial role in efficiently updating the parameters of a CNN during training. These algorithms help in navigating the high-dimensional parameter space to find the optimal set of weights that minimize the loss function. Common optimization algorithms used in training CNNs include Adam, Stochastic Gradient Descent (SGD), and RMSprop.
Adam is a popular optimization algorithm that combines the benefits of adaptive learning rates and momentum to accelerate convergence and improve training efficiency. By adjusting the learning rate for each parameter based on past gradients, Adam can adapt to different types of data and network architectures, leading to faster convergence and better generalization.
SGD is a classic optimization algorithm that updates the network parameters based on the gradient of the loss function with respect to each parameter. Despite its simplicity, SGD is widely used in training neural networks due to its effectiveness in finding optimal solutions. However, SGD can suffer from slow convergence and oscillations in the loss landscape.
RMSprop is another optimization algorithm that addresses the limitations of SGD by adapting the learning rate for each parameter based on the magnitude of recent gradients. By normalizing the gradients using an exponentially decaying average, RMSprop can converge faster and handle non-stationary objectives more effectively.
Choosing the right optimization algorithm is crucial for training CNNs effectively and achieving high performance on various tasks. The selection of an optimization algorithm depends on factors like the dataset size, network architecture, and computational resources available for training. Experimenting with different optimization algorithms and tuning their hyperparameters can help optimize the training process and improve the overall performance of CNNs.
Practical Applications
Image Recognition
Image recognition is one of the most prominent applications of Convolutional Neural Networks (CNNs), showcasing their ability to classify and identify objects within images. CNNs have been instrumental in achieving state-of-the-art results in tasks like facial recognition, object classification, and scene understanding.
By leveraging the hierarchical feature extraction capabilities of CNNs, image recognition systems can learn to distinguish between different objects, shapes, and textures present in images. This enables applications like automatic image tagging, content-based image retrieval, and visual search, revolutionizing the way we interact with visual data.
One of the key advantages of using CNNs for image recognition is their ability to handle complex and high-dimensional data, such as color images with varying textures and backgrounds. CNNs can automatically learn relevant features from raw pixel values, eliminating the need for manual feature engineering and simplifying the overall image recognition pipeline.
practical implementations of image recognition using CNNs can be found in various industries, including e-commerce, healthcare, security, and entertainment. From identifying products in online stores to diagnosing medical conditions from medical images, CNN-based image recognition systems are transforming how we analyze and interpret visual data.
Object Detection
Object detection is another critical application of Convolutional Neural Networks (CNNs) that involves identifying and localizing objects within images or videos. CNNs have been at the forefront of advancements in object detection, enabling tasks like pedestrian detection, vehicle tracking, and surveillance monitoring.
By combining the capabilities of convolutional layers for feature extraction and pooling layers for spatial downsampling, CNNs can effectively detect objects of varying sizes and orientations in complex scenes. This allows for real-time object detection in video streams, enabling applications like autonomous driving, security surveillance, and augmented reality.
Object detection systems based on CNNs typically involve the use of region proposal networks, which generate candidate object bounding boxes in the input image. These proposals are then refined and classified by a separate network, leading to accurate object localization and classification. This two-stage approach has significantly improved the accuracy and efficiency of object detection systems.
Practical implementations of object detection using CNNs can be seen in a wide range of industries, including retail, transportation, agriculture, and robotics. From tracking inventory in warehouses to monitoring crop health in agricultural fields, CNN-powered object detection systems are driving innovation and efficiency in various domains.
Medical Imaging
Medical imaging is a critical application of Convolutional Neural Networks (CNNs) that has the potential to revolutionize healthcare diagnostics and treatment. CNNs have shown remarkable performance in tasks like disease diagnosis, tumor detection, and medical image segmentation, offering new insights and capabilities to healthcare professionals.
By analyzing medical images such as X-rays, MRIs, and CT scans, CNNs can assist in identifying abnormalities, lesions, and other medical conditions with high accuracy. This enables early detection of diseases, personalized treatment planning, and improved patient outcomes, making CNNs invaluable tools in the field of medical imaging.
One of the key advantages of using CNNs for medical imaging is their ability to learn complex patterns and relationships from large volumes of image data. CNNs can automatically extract features indicative of specific medical conditions, aiding radiologists and clinicians in making informed decisions and diagnoses.
Practical implementations of CNNs in medical imaging can be found in hospitals, clinics, research institutions, and telemedicine platforms. From assisting radiologists in interpreting medical images to facilitating remote consultations and second opinions, CNN-powered medical imaging systems are enhancing the quality and efficiency of healthcare delivery.
Performance Evaluation
When it comes to evaluating the performance of Convolutional Neural Networks (CNNs), accuracy metrics play a crucial role. These metrics measure the model’s ability to correctly classify images and make accurate predictions. Achieving high accuracy is a key objective in training CNNs, as it indicates the model’s proficiency in recognizing patterns and features within visual data.
Accuracy metrics in CNNs are typically calculated by comparing the model’s predictions to the ground truth labels in a dataset. Common metrics used for evaluating classification tasks include accuracy, precision, recall, and f1 score. These metrics provide insights into different aspects of the model’s performance, such as its ability to correctly identify true positives, false positives, true negatives, and false negatives.
In addition to traditional accuracy metrics, CNNs are also evaluated based on their inference speed. Inference speed refers to the time taken by the model to process input data and generate predictions. Fast inference speed is essential for real-time applications like autonomous driving, surveillance systems, and augmented reality, where quick decision-making is critical.
Improving inference speed in CNNs involves optimizing the model’s architecture, reducing computational complexity, and leveraging hardware accelerators like GPUs and TPUs. Techniques like model quantization, pruning, and parallelization can also help enhance the efficiency of CNNs and speed up the inference process.
Overall, evaluating the performance of CNNs requires a comprehensive analysis of both accuracy metrics and inference speed. By striking a balance between accuracy and speed, researchers and practitioners can develop CNN models that deliver high-quality predictions in a timely manner, advancing the capabilities of deep learning in various domains.
Challenges and Limitations
Overfitting
One of the primary challenges faced in training Convolutional Neural Networks (CNNs) is overfitting. Overfitting occurs when a model performs exceptionally well on the training data but fails to generalize to unseen examples. This phenomenon can lead to reduced performance and accuracy in real-world applications, where the model needs to make predictions on new, unseen data.
Overfitting typically occurs when a CNN learns noise and irrelevant patterns from the training data, instead of capturing the underlying relationships that generalize well to new instances. This can result in the model memorizing the training data rather than learning to make accurate predictions based on the underlying features.
To address the issue of overfitting in CNNs, various techniques can be employed during the training process. One common approach is to introduce regularization methods such as dropout, which randomly deactivates neurons during training to prevent the network from relying too heavily on specific features. By introducing randomness in the network’s behavior, dropout helps in improving generalization and reducing overfitting.
Another technique to combat overfitting is early stopping, where the training process is halted once the model’s performance on a validation set starts to deteriorate. By monitoring the model’s performance on a separate validation set during training, early stopping prevents the model from overfitting to the training data and ensures that it generalizes well to unseen examples.
Data augmentation is another effective strategy to mitigate overfitting in CNNs. By artificially increasing the diversity of the training data through transformations like rotation, flipping, and scaling, data augmentation helps the model learn robust features that are invariant to such variations. This augmentation process introduces variability in the training data, making the model more resilient to overfitting and improving its generalization capabilities.
Overall, addressing the challenge of overfitting in CNNs is crucial for ensuring the model’s performance on unseen data and real-world applications. By implementing regularization techniques, early stopping, and data augmentation strategies, researchers and practitioners can develop CNN models that generalize well and make accurate predictions in diverse scenarios.
Data Augmentation
Data augmentation plays a vital role in enhancing the robustness and generalization capabilities of Convolutional Neural Networks (CNNs). By artificially increasing the diversity of the training data, data augmentation helps the model learn invariant features that are essential for making accurate predictions on unseen examples.
One of the key benefits of data augmentation is its ability to introduce variability in the training data without the need for collecting additional labeled samples. By applying transformations like rotation, flipping, and scaling to the existing training data, data augmentation creates new training instances that expose the model to different variations of the same underlying patterns.
Augmenting the training data helps in reducing the risk of overfitting, where the model memorizes the training data rather than learning to generalize to new instances. By presenting the model with augmented samples that exhibit variations in lighting, orientation, and background, data augmentation encourages the network to focus on the essential features that are invariant to such changes.
Common data augmentation techniques used in CNN training include random cropping, translation, and color jittering, which introduce controlled variations in the input data. These transformations help the model learn to recognize objects and patterns regardless of their exact position or appearance, leading to improved generalization and robustness.
Furthermore, data augmentation can also help in addressing class imbalance issues in the training data by generating synthetic samples for underrepresented classes. By creating augmented instances of minority classes, data augmentation ensures that the model receives sufficient exposure to all classes, preventing bias and improving the model’s performance on rare examples.
Overall, data augmentation is a powerful technique for enhancing the performance and Reliability of CNNs in various tasks. By diversifying the training data and exposing the model to a wide range of variations, data augmentation enables CNNs to learn robust features and generalize effectively to unseen examples, ultimately improving their accuracy and performance in real-world applications.
Future Trends
As we look towards the future of Convolutional Neural Networks (CNNs), several research directions are emerging that aim to further enhance the capabilities and applications of these powerful deep learning models. Researchers and practitioners are actively exploring new architectures, optimization techniques, and applications in diverse fields to push the boundaries of CNN technology.
Research Directions
One of the key research directions in the field of CNNs is the development of novel architectures that can handle increasingly complex tasks and datasets. Researchers are investigating the use of attention mechanisms, transformer networks, and capsule networks to improve the interpretability and efficiency of CNNs. These architectural innovations aim to address challenges like long-range dependencies, spatial hierarchies, and memory constraints in deep learning models.
Furthermore, researchers are exploring the integration of CNNs with other types of neural networks, such as recurrent neural networks (RNNs) and generative adversarial networks (gans), to create hybrid models with enhanced capabilities. By combining the strengths of different neural network architectures, researchers hope to achieve breakthroughs in areas like video understanding, natural language processing, and reinforcement learning.
Another research direction in CNNs is the development of more efficient and scalable optimization algorithms that can accelerate training and improve convergence. Researchers are investigating techniques like meta-learning, evolutionary algorithms, and automatic hyperparameter tuning to optimize the performance of CNNs across a wide range of tasks and datasets. These optimization advancements aim to make CNNs more adaptable, robust, and capable of handling real-world challenges.
Moreover, researchers are focusing on expanding the applications of CNNs in emerging fields like augmented reality, robotics, and natural language processing. By exploring new use cases and domains for CNN technology, researchers aim to unlock the full potential of these models in solving complex problems and driving innovation in various industries. The integration of CNNs with cutting-edge technologies like 5G, IoT, and edge computing is also opening up new opportunities for deploying CNNs in real-time, resource-constrained environments.
Industry Adoption
In addition to research advancements, industry adoption of Convolutional Neural Networks (CNNs) is expected to grow significantly in the coming years, driven by the increasing demand for AI-powered solutions across various sectors. Industries like healthcare, finance, automotive, and entertainment are leveraging CNN technology to enhance decision-making, improve efficiency, and deliver innovative products and services.
In the healthcare industry, CNNs are being used for medical image analysis, disease diagnosis, and personalized treatment planning. By leveraging the power of CNNs to analyze complex medical images and identify patterns indicative of diseases, healthcare professionals can make more accurate diagnoses and provide tailored treatment options to patients. The adoption of CNNs in healthcare is expected to revolutionize diagnostics, improve patient outcomes, and drive advancements in precision medicine.
In the finance sector, CNNs are being deployed for fraud detection, risk assessment, and algorithmic trading. By analyzing large volumes of financial data and detecting anomalies or patterns indicative of fraudulent activities, CNNs can help financial institutions mitigate risks, enhance security, and streamline decision-making processes. The adoption of CNNs in finance is expected to improve regulatory compliance, reduce operational costs, and enhance the overall efficiency of financial services.
In the automotive industry, CNNs are playing a crucial role in autonomous driving, driver assistance systems, and vehicle Safety. By processing data from sensors like cameras, LiDAR, and radar, CNNs can detect objects, predict trajectories, and make real-time decisions to ensure safe and efficient driving experiences. The adoption of CNNs in automotive applications is expected to accelerate the development of self-driving technologies, improve road safety, and transform the future of transportation.
Furthermore, in the entertainment industry, CNNs are being used for content recommendation, personalized advertising, and content creation. By analyzing user preferences, behavior patterns, and content features, CNNs can deliver tailored recommendations, targeted advertisements, and engaging multimedia experiences to audiences. The adoption of CNNs in entertainment is expected to enhance user engagement, drive content discovery, and revolutionize the way content is consumed and distributed.
Overall, the future of Convolutional Neural Networks (CNNs) is bright, with ongoing research efforts and increasing industry adoption paving the way for new advancements and applications. By staying at the forefront of innovation and collaboration between academia and industry, CNN technology is poised to continue shaping the future of AI and driving transformative changes across diverse sectors.
Conclusion
Convolutional Neural Networks (CNNs) have revolutionized the field of deep learning, particularly in image processing and computer vision. By mimicking the visual cortex of the human brain, CNNs excel in tasks like image recognition, object detection, and medical imaging. The architectural design, training process, and practical applications of CNNs showcase their versatility and impact across various domains. Despite challenges like overfitting, techniques such as data augmentation help enhance the robustness of CNNs. Looking ahead, future trends in CNN research focus on exploring new architectures and applications in emerging fields like augmented reality and robotics. The widespread adoption of CNNs in industries like healthcare and finance is expected to drive innovation and advancements in AI technology, making CNNs a powerful tool for creating intelligent systems that enhance our daily lives.


Comments